
Всем привет! В последнее время все чаще от коллег слышу о требовании в ТЗ оценивать качество текста по закону Ципфа. И далеко не все понимают, как нужно редактировать текст под этот закон. В сегодняшней статье попробую рассказать, как наиболее простым способом улучшить параметр, а также уточню почему хорошим авторам на самом деле это не нужно.
Определить качество текста по закону Ципфа можно по нескольким сервисам. Но, наиболее адекватным я считаю PR-CY, тут сочетается правильная формула с простым и понятным интерфейсом. Именно его я и использовал при подготовке этого материала.
Что такое закон Ципфа
Для начала стоит разобраться, что это такое. Если верить Википедии, сформулировал эту закономерность в 1908 году Жан-Батист Эсту, первоначально относился этот закон к стенографии. Первое известное широкой общественности применение закономерности относится к демографии, а точнее к распределению численности населения в городах, использовал ее Феликс Ауэрбах.
Современное название закономерность получила в 1949 году благодаря лингвисту Джорджу Ципфу. Он показал с ее помощью градацию распределения богатства среди населения. И только потом закон стали применять для определения читабельности текстов.
Как рассчитывается
Чтобы правильно использовать этот закон нужно понимать, как он работает. Разберем формулу для расчета.
FR=C
Где:
- F – частота использования слова;
- R – порядковый номер;
- C – постоянная величина (число обозначающее самое большое по количеству повторов слово).
На практике более удобной оказывается другая формула, она выглядит понятнее.
F=C/R
Удобнее такой подход так как у нас есть данные по числу повтора максимально распространенного слова. Именно от этого количества и отталкиваются.
Если упростить, то в нашем тексте второе по повторяемости слово должно встречаться в два раза реже, чем первое. Идущее на третьем месте, в три раза и так далее.
Пример подгонки текста
С теорией немного разобрались. Осталось разобраться с практикой. В качестве подопытного текста взял статью из Т-Ж. Почему именно оттуда? Все просто. На текущий момент это один из лучших образчиков любимого многими инфостиля. Ну, и было интересно, что покажет текст, написанный под руководством Максима Ильяхова. Скажу сразу, тексты по этому показателю на уровне, хотя, перелопатив более 40 сайтов вообще не нашел ни одной статьи с плохой естественностью. Также, сразу забегу вперед и скажу, что подопытный текст после подгонки стал намного хуже, несмотря на улучшенный показатель по Ципфа, не стоит сильно заморачиваться по чрезмерному повышению естественности.
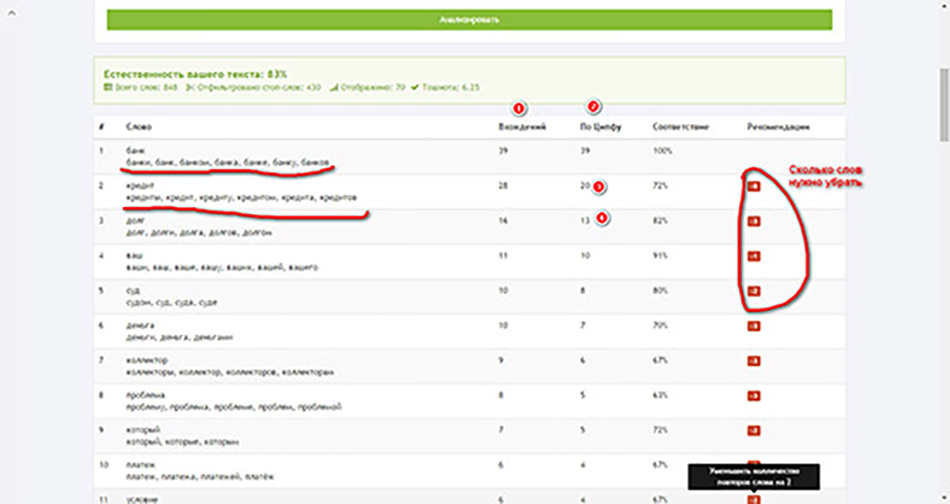
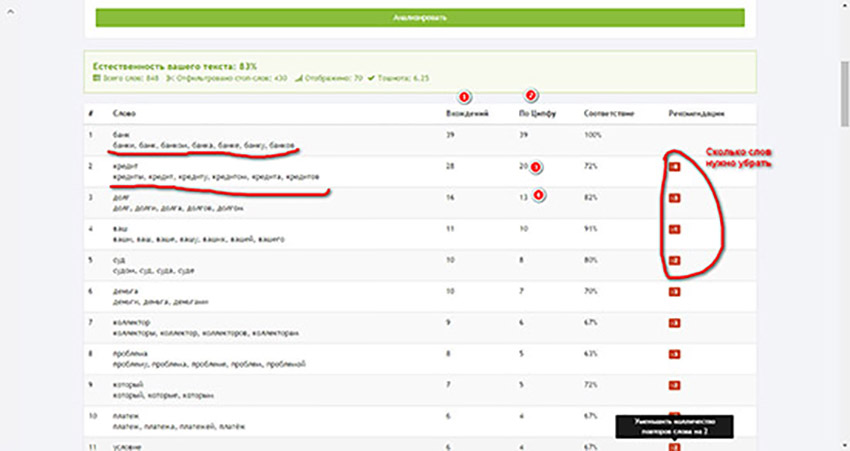
Вот что нам показал анализатор после проверки.
{kind=link}
Разберем, что там указано. Как видим есть столбец со словами, а также непонятные цифры. В столбце «вхождения» (1) указано сколько раз встречаются словоформы в тексте. В столбце «по Ципфу» (2) рекомендованное количество вхождений. Маркерами 3 и 4 помечены идеальные показатели для второй и третьей позиции. Также стоит обратить внимание на рекомендации, здесь указано сколько слов нужно убрать для достижения идеального сочетания.
Для большего понимания разберем, что насчитал анализатор. За основу возьмем цифру 39 (C), также нам понадобится порядковый номер, обратим внимание на 2 (F) позицию. Берем формулу.
F=C/R
Подставляем.
F=39/2=19,5
Округляем в большую сторону и получаем 20, это и будет необходимым количеством вхождений. Что подтверждает и анализатор. У нас же второе по популярности слово употребляется 28 раз, соответственно 8 повторов нужно будет удалить или заменить.

Разобравшись с принципом работы закона начинаем редактировать. Для этого удаляем или заменяем на синонимы слова, у которых больше вхождений, чем это требуется по Ципфа. В результате получаем вот такую картину.
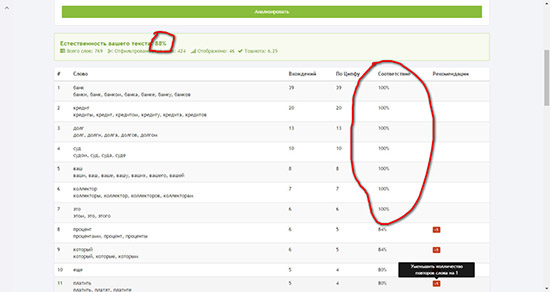{kind=link}
Как видите, мне удалось увеличить показатель с 83% до 88%. Но, при этом значительно пострадало качество текста. Не стоит стремиться к увеличению этого показателя до 100%. По факту, если у вас уже есть 75%, это отлично и дальше извращаться не стоит.
Ципфа и SEO
Теперь перейдем к тому, зачем требуется знание этой закономерности копирайтеру. Сеошники заказывая тексты стремятся сделать их наиболее удобными для поисковых систем. Считается (правда, непонятно кем), что закон Ципфа активно используется поисковыми алгоритмами. Доказать или опровергнуть это утверждение сложно. Никаких вменяемых исследований и экспериментов на эту тему мне найти не удалось.
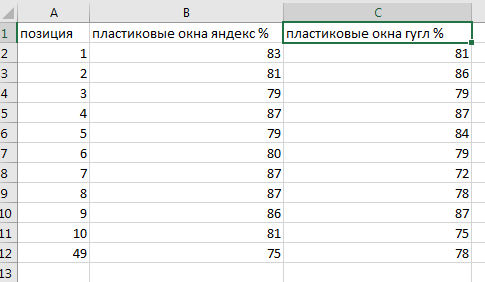
Решил проверить самостоятельно. Для этого взял выдачу по такому конкурентному запросу «пластиковые окна», в Яндексе бралась московская выдача, в Гугле пришлось поколдовать, и он меня вроде тоже определил, как жителя столицы (по крайней мере рекламу мне показал с московской геолокацией). Брал первую страницу выдачи, плюс 49 место. Получилась вот такая табличка.
Если посмотреть внимательнее, можно обратить внимание, в Яндексе выдача более ровная, если смотреть на исследуемую нами закономерность. Но, при этом более высокий показатель не гарантирует победы в борьбе за первое место в топе.
На основании этого можно сказать, если поисковики и применяют данный закон, является он только одним из факторов. И не основным.
Выводы
Ну, вот и все. Теперь вы знаете, что такое качество текста по закону Ципфа, а также можете корректировать этот показатель. На самом деле тут нет ничего сложного, все достаточно просто. Достаточно один раз понять принцип работы этой закономерности.
Спасибо за статью, интересно было ознакомиться! Только у меня скриншоты проверки почти не увеличиваются, сложно разобрать, что там написано, даже цифры (((
И тут это… заинтриговали проверкой текста МИ, а насколько изменилось абстрактное качество – непонятно… Хотелось бы пример, хоть огрызочек какой-нибудь…
Скрины поправил, но видимо из-за всех манипуляций все равно немного мутно получилось. Выкладывать кусочки не буду, ибо у меня нет договоренности с Максом на такое использование его текстов. Могу привести пример, мне пришлось убрать практически все упоминания о коллекторах, в итоге из текста понятно, что проблемы возникают с какими-то людьми, но непонятно кто они.
Привет, спасибо очень интересная статья. Только тоже не видно скриншотов (((
Поправил.
О, а я, оказывается, с этим сталкивалась. Только ни про какой закон не указывалось, просто во время проверки рекомендовали снизить или увеличить количество определенных слов :))))
Это сейчас частая фишка.
расскажу вам секрет, как сеошник. Берете сервис Миратекст семантический анализ и меняете текст, пока облако тегов не покажет ключи жирными и ципфа от 55% и выше) Это хорошо.
Если судить по Miratex у этого текста всего 40% качества по закону Ципфа
Миратекстом никогда не пользовался. Да и большой отклик читателей говорит, что с текстом все нормально.
Вы попали в самую точку. Мне кажется это хорошая мысль. Я согласен с Вами.